[Work in progress]
Reference audio vs noisy recordings
As expected, each service performs better on audio recorded in a quiet setting.
IBM and Google performed about the same over high quality audio recorded in a quiet setting using a medium quality microphone.
IBM was better able to generate transcripts for my lower quality recordings obtained in noisy settings.
This could be due to a custom (which they refer to as a "narrowband") setting that IBM provides that is specifically provided to accommodate low-bitrate recordings. That setting also tends to generate longer transcripts for higher bitrate recordings that are especially noisy.
It may also have to do with the encoding used. I needed to transcode every audio file to the encoding required by Google's service, and it is possible that this transcoding step could be tuned to give better accuracy. I haven't attempted any rigorous tuning of either service at this stage of my experiments.
This is a work in progress. I am hoping to do a direct file-by-file comparison of the two services once I am confident that I am configuring my settings to use Google's api to the best of its capability. However I have obtained some cursory comparisons on the current results.
Processing seconds per minute : about the same
IBM and Google process the audio in about the same amount of time. Google is somewhat faster at the actual transcription processing. However, Google requires that the file be uploaded to Google Storage first.
IBM Transcribed/Processed : 7281/8415
IBM was able to transcribe 87% of the files submitted.
Google Transcribed/Processed : 3521/8415
The transcription rate (42%) was lower for two main reasons.
The first was a file size limit. Files larger than ~80MB require a prior arrangement, whereas IBM was able to process files of all sizes submitted to the service.
The second main reason is that IBM has a custom setting for low-bit rate recordings. Google failed to generate a transcript for many files that were below the file size limit.
Transcript words per minute of audio (IBM/Google) : 102.0/9.8
Google's api doesn't have a setting for handling low-bitrate recordings similar to IBM's narrowband setting. The number of transcript words generated per minute of audio was much lower for Google even after adjusting for transcription rate.
Comparison on reference documents
The following comparisons were made over 245 reference documents. The reference transcripts were transcribed using a speech-to-text transcription software that was trained to my voice, in a quiet environment, using a hand-held medium quality wired microphone. Most of the errors were manually corrected.
Google generated a transcript for 210 out of the 245 reference documents (86%), and IBM generated a transcript for 243 of the 245 (99%). The Bleu scores over these reference documents are fairly comparable, with IBM performing slightly better.

When measured using Ratcliff-Obershelp similarity, Google fares slightly better across the board.

Comparison over all audio
This section analyzes the number of transcripts that are generated, and the number of words per transcript.
This comparison was over 8,415 audio files that were submitted to each service.
Marked differences between IBM Watson and Google transcription arise when comparing transcription rates and number of words generated when run on audio collected out in the wild. Of 8,415 such audio, IBM generated transcripts for 7,227, while Google was able to generate a transcript for 3,521.
Total Word Counts
Out of 8,415 audio files attempted, Google generated 3,521 transcripts. Those 3,521 transcripts contain total of 485,334 words, an average of 137 words per transcript.
IBM Watson generated 7,227 transcripts, extracting 9,511,743 words out of those transcripts. This gives an average of 1,316 words per transcript.
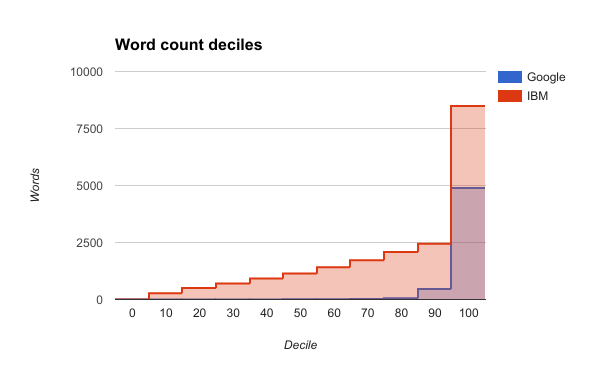
Word Count Deciles
Many of these transcripts that Google failed to generate were simply due to the file size exceeding quota.
However Google also failed to generate any transcript words for many other files that did not exceed the file size quota. It also generated a much lower word count per transcript for audio that was from a noisy or low bit rate recording.
One way to illustrate this is by examining the word count deciles over the transcripts that were successfully generated.
The following table gives the word counts deciles over the transcripts generated by each service.
| API | min | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | max |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 2 | 3 | 5 | 8 | 12 | 19 | 58 | 459 | 4892 | |
| IBM | 1 | 278 | 501 | 698 | 916 | 1137 | 1409 | 1722 | 2080 | 2450 | 8490 |